第一篇文章啊,现在看看有瑕疵,也是我的进步…
这里记录一下组合方法,防止以后需要复盘(虽然这也是忘记后再想出来的)。
RepVGG完整代码
import torch.nn as nn
import numpy as np
import torch
import copy
from se_block import SEBlock
import torch.utils.checkpoint as checkpoint
def conv_bn(in_channels, out_channels, kernel_size, stride, padding, groups=1):
result = nn.Sequential()
result.add_module('conv', nn.Conv2d(in_channels=in_channels, out_channels=out_channels,
kernel_size=kernel_size, stride=stride, padding=padding, groups=groups, bias=False))
result.add_module('bn', nn.BatchNorm2d(num_features=out_channels))
return result
class RepVGGBlock(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size,
stride=1, padding=0, dilation=1, groups=1, padding_mode='zeros', deploy=False, use_se=False):
super(RepVGGBlock, self).__init__()
self.deploy = deploy
self.groups = groups
self.in_channels = in_channels
assert kernel_size == 3
assert padding == 1
padding_11 = padding - kernel_size // 2
self.nonlinearity = nn.ReLU()
if use_se:
# Note that RepVGG-D2se uses SE before nonlinearity. But RepVGGplus models uses SE after nonlinearity.
self.se = SEBlock(out_channels, internal_neurons=out_channels // 16)
else:
self.se = nn.Identity()
if deploy:
self.rbr_reparam = nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size, stride=stride,
padding=padding, dilation=dilation, groups=groups, bias=True, padding_mode=padding_mode)
else:
self.rbr_identity = nn.BatchNorm2d(num_features=in_channels) if out_channels == in_channels and stride == 1 else None
self.rbr_dense = conv_bn(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size, stride=stride, padding=padding, groups=groups)
self.rbr_1x1 = conv_bn(in_channels=in_channels, out_channels=out_channels, kernel_size=1, stride=stride, padding=padding_11, groups=groups)
print('RepVGG Block, identity = ', self.rbr_identity)
def forward(self, inputs):
if hasattr(self, 'rbr_reparam'):
return self.nonlinearity(self.se(self.rbr_reparam(inputs)))
if self.rbr_identity is None:
id_out = 0
else:
id_out = self.rbr_identity(inputs)
return self.nonlinearity(self.se(self.rbr_dense(inputs) + self.rbr_1x1(inputs) + id_out))
# Optional. This may improve the accuracy and facilitates quantization in some cases.
# 1. Cancel the original weight decay on rbr_dense.conv.weight and rbr_1x1.conv.weight.
# 2. Use like this.
# loss = criterion(....)
# for every RepVGGBlock blk:
# loss += weight_decay_coefficient * 0.5 * blk.get_cust_L2()
# optimizer.zero_grad()
# loss.backward()
def get_custom_L2(self):
K3 = self.rbr_dense.conv.weight
K1 = self.rbr_1x1.conv.weight
t3 = (self.rbr_dense.bn.weight / ((self.rbr_dense.bn.running_var + self.rbr_dense.bn.eps).sqrt())).reshape(-1, 1, 1, 1).detach()
t1 = (self.rbr_1x1.bn.weight / ((self.rbr_1x1.bn.running_var + self.rbr_1x1.bn.eps).sqrt())).reshape(-1, 1, 1, 1).detach()
l2_loss_circle = (K3 ** 2).sum() - (K3[:, :, 1:2, 1:2] ** 2).sum() # The L2 loss of the "circle" of weights in 3x3 kernel. Use regular L2 on them.
eq_kernel = K3[:, :, 1:2, 1:2] * t3 + K1 * t1 # The equivalent resultant central point of 3x3 kernel.
l2_loss_eq_kernel = (eq_kernel ** 2 / (t3 ** 2 + t1 ** 2)).sum() # Normalize for an L2 coefficient comparable to regular L2.
return l2_loss_eq_kernel + l2_loss_circle
# This func derives the equivalent kernel and bias in a DIFFERENTIABLE way.
# You can get the equivalent kernel and bias at any time and do whatever you want,
# for example, apply some penalties or constraints during training, just like you do to the other models.
# May be useful for quantization or pruning.
def get_equivalent_kernel_bias(self):
kernel3x3, bias3x3 = self._fuse_bn_tensor(self.rbr_dense)
kernel1x1, bias1x1 = self._fuse_bn_tensor(self.rbr_1x1)
kernelid, biasid = self._fuse_bn_tensor(self.rbr_identity)
return kernel3x3 + self._pad_1x1_to_3x3_tensor(kernel1x1) + kernelid, bias3x3 + bias1x1 + biasid
def _pad_1x1_to_3x3_tensor(self, kernel1x1):
if kernel1x1 is None:
return 0
else:
return torch.nn.functional.pad(kernel1x1, [1,1,1,1])
def _fuse_bn_tensor(self, branch):
if branch is None:
return 0, 0
if isinstance(branch, nn.Sequential):
kernel = branch.conv.weight
running_mean = branch.bn.running_mean
running_var = branch.bn.running_var
gamma = branch.bn.weight
beta = branch.bn.bias
eps = branch.bn.eps
else:
assert isinstance(branch, nn.BatchNorm2d)
if not hasattr(self, 'id_tensor'):
input_dim = self.in_channels // self.groups
kernel_value = np.zeros((self.in_channels, input_dim, 3, 3), dtype=np.float32)
for i in range(self.in_channels):
kernel_value[i, i % input_dim, 1, 1] = 1
self.id_tensor = torch.from_numpy(kernel_value).to(branch.weight.device)
kernel = self.id_tensor
running_mean = branch.running_mean
running_var = branch.running_var
gamma = branch.weight
beta = branch.bias
eps = branch.eps
std = (running_var + eps).sqrt()
t = (gamma / std).reshape(-1, 1, 1, 1)
return kernel * t, beta - running_mean * gamma / std
def switch_to_deploy(self):
if hasattr(self, 'rbr_reparam'):
return
kernel, bias = self.get_equivalent_kernel_bias()
self.rbr_reparam = nn.Conv2d(in_channels=self.rbr_dense.conv.in_channels, out_channels=self.rbr_dense.conv.out_channels,
kernel_size=self.rbr_dense.conv.kernel_size, stride=self.rbr_dense.conv.stride,
padding=self.rbr_dense.conv.padding, dilation=self.rbr_dense.conv.dilation, groups=self.rbr_dense.conv.groups, bias=True)
self.rbr_reparam.weight.data = kernel
self.rbr_reparam.bias.data = bias
self.__delattr__('rbr_dense')
self.__delattr__('rbr_1x1')
if hasattr(self, 'rbr_identity'):
self.__delattr__('rbr_identity')
if hasattr(self, 'id_tensor'):
self.__delattr__('id_tensor')
self.deploy = True
class RepVGG(nn.Module):
def __init__(self, num_blocks, num_classes=1000, width_multiplier=None, override_groups_map=None, deploy=False, use_se=False, use_checkpoint=False):
super(RepVGG, self).__init__()
assert len(width_multiplier) == 4
self.deploy = deploy
self.override_groups_map = override_groups_map or dict()
assert 0 not in self.override_groups_map
self.use_se = use_se
self.use_checkpoint = use_checkpoint
self.in_planes = min(64, int(64 * width_multiplier[0]))
self.stage0 = RepVGGBlock(in_channels=3, out_channels=self.in_planes, kernel_size=3, stride=2, padding=1, deploy=self.deploy, use_se=self.use_se)
self.cur_layer_idx = 1
self.stage1 = self._make_stage(int(64 * width_multiplier[0]), num_blocks[0], stride=2)
self.stage2 = self._make_stage(int(128 * width_multiplier[1]), num_blocks[1], stride=2)
self.stage3 = self._make_stage(int(256 * width_multiplier[2]), num_blocks[2], stride=2)
self.stage4 = self._make_stage(int(512 * width_multiplier[3]), num_blocks[3], stride=2)
self.gap = nn.AdaptiveAvgPool2d(output_size=1)
self.linear = nn.Linear(int(512 * width_multiplier[3]), num_classes)
def _make_stage(self, planes, num_blocks, stride):
strides = [stride] + [1]*(num_blocks-1)
blocks = []
for stride in strides:
cur_groups = self.override_groups_map.get(self.cur_layer_idx, 1)
blocks.append(RepVGGBlock(in_channels=self.in_planes, out_channels=planes, kernel_size=3,
stride=stride, padding=1, groups=cur_groups, deploy=self.deploy, use_se=self.use_se))
self.in_planes = planes
self.cur_layer_idx += 1
return nn.ModuleList(blocks)
def forward(self, x):
out = self.stage0(x)
for stage in (self.stage1, self.stage2, self.stage3, self.stage4):
for block in stage:
if self.use_checkpoint:
out = checkpoint.checkpoint(block, out)
else:
out = block(out)
out = self.gap(out)
out = out.view(out.size(0), -1)
out = self.linear(out)
return out
optional_groupwise_layers = [2, 4, 6, 8, 10, 12, 14, 16, 18, 20, 22, 24, 26]
g2_map = {l: 2 for l in optional_groupwise_layers}
g4_map = {l: 4 for l in optional_groupwise_layers}
def create_RepVGG_A0(deploy=False, use_checkpoint=False):
return RepVGG(num_blocks=[2, 4, 14, 1], num_classes=1000,
width_multiplier=[0.75, 0.75, 0.75, 2.5], override_groups_map=None, deploy=deploy, use_checkpoint=use_checkpoint)
def create_RepVGG_A1(deploy=False, use_checkpoint=False):
return RepVGG(num_blocks=[2, 4, 14, 1], num_classes=1000,
width_multiplier=[1, 1, 1, 2.5], override_groups_map=None, deploy=deploy, use_checkpoint=use_checkpoint)
def create_RepVGG_A2(deploy=False, use_checkpoint=False):
return RepVGG(num_blocks=[2, 4, 14, 1], num_classes=1000,
width_multiplier=[1.5, 1.5, 1.5, 2.75], override_groups_map=None, deploy=deploy, use_checkpoint=use_checkpoint)
def create_RepVGG_B0(deploy=False, use_checkpoint=False):
return RepVGG(num_blocks=[4, 6, 16, 1], num_classes=1000,
width_multiplier=[1, 1, 1, 2.5], override_groups_map=None, deploy=deploy, use_checkpoint=use_checkpoint)
def create_RepVGG_B1(deploy=False, use_checkpoint=False):
return RepVGG(num_blocks=[4, 6, 16, 1], num_classes=1000,
width_multiplier=[2, 2, 2, 4], override_groups_map=None, deploy=deploy, use_checkpoint=use_checkpoint)
def create_RepVGG_B1g2(deploy=False, use_checkpoint=False):
return RepVGG(num_blocks=[4, 6, 16, 1], num_classes=1000,
width_multiplier=[2, 2, 2, 4], override_groups_map=g2_map, deploy=deploy, use_checkpoint=use_checkpoint)
def create_RepVGG_B1g4(deploy=False, use_checkpoint=False):
return RepVGG(num_blocks=[4, 6, 16, 1], num_classes=1000,
width_multiplier=[2, 2, 2, 4], override_groups_map=g4_map, deploy=deploy, use_checkpoint=use_checkpoint)
def create_RepVGG_B2(deploy=False, use_checkpoint=False):
return RepVGG(num_blocks=[4, 6, 16, 1], num_classes=1000,
width_multiplier=[2.5, 2.5, 2.5, 5], override_groups_map=None, deploy=deploy, use_checkpoint=use_checkpoint)
def create_RepVGG_B2g2(deploy=False, use_checkpoint=False):
return RepVGG(num_blocks=[4, 6, 16, 1], num_classes=1000,
width_multiplier=[2.5, 2.5, 2.5, 5], override_groups_map=g2_map, deploy=deploy, use_checkpoint=use_checkpoint)
def create_RepVGG_B2g4(deploy=False, use_checkpoint=False):
return RepVGG(num_blocks=[4, 6, 16, 1], num_classes=1000,
width_multiplier=[2.5, 2.5, 2.5, 5], override_groups_map=g4_map, deploy=deploy, use_checkpoint=use_checkpoint)
def create_RepVGG_B3(deploy=False, use_checkpoint=False):
return RepVGG(num_blocks=[4, 6, 16, 1], num_classes=1000,
width_multiplier=[3, 3, 3, 5], override_groups_map=None, deploy=deploy, use_checkpoint=use_checkpoint)
def create_RepVGG_B3g2(deploy=False, use_checkpoint=False):
return RepVGG(num_blocks=[4, 6, 16, 1], num_classes=1000,
width_multiplier=[3, 3, 3, 5], override_groups_map=g2_map, deploy=deploy, use_checkpoint=use_checkpoint)
def create_RepVGG_B3g4(deploy=False, use_checkpoint=False):
return RepVGG(num_blocks=[4, 6, 16, 1], num_classes=1000,
width_multiplier=[3, 3, 3, 5], override_groups_map=g4_map, deploy=deploy, use_checkpoint=use_checkpoint)
def create_RepVGG_D2se(deploy=False, use_checkpoint=False):
return RepVGG(num_blocks=[8, 14, 24, 1], num_classes=1000,
width_multiplier=[2.5, 2.5, 2.5, 5], override_groups_map=None, deploy=deploy, use_se=True, use_checkpoint=use_checkpoint)
func_dict = {
'RepVGG-A0': create_RepVGG_A0,
'RepVGG-A1': create_RepVGG_A1,
'RepVGG-A2': create_RepVGG_A2,
'RepVGG-B0': create_RepVGG_B0,
'RepVGG-B1': create_RepVGG_B1,
'RepVGG-B1g2': create_RepVGG_B1g2,
'RepVGG-B1g4': create_RepVGG_B1g4,
'RepVGG-B2': create_RepVGG_B2,
'RepVGG-B2g2': create_RepVGG_B2g2,
'RepVGG-B2g4': create_RepVGG_B2g4,
'RepVGG-B3': create_RepVGG_B3,
'RepVGG-B3g2': create_RepVGG_B3g2,
'RepVGG-B3g4': create_RepVGG_B3g4,
'RepVGG-D2se': create_RepVGG_D2se, # Updated at April 25, 2021. This is not reported in the CVPR paper.
}
def get_RepVGG_func_by_name(name):
return func_dict[name]
# Use this for converting a RepVGG model or a bigger model with RepVGG as its component
# Use like this
# model = create_RepVGG_A0(deploy=False)
# train model or load weights
# repvgg_model_convert(model, save_path='repvgg_deploy.pth')
# If you want to preserve the original model, call with do_copy=True
# ====================== for using RepVGG as the backbone of a bigger model, e.g., PSPNet, the pseudo code will be like
# train_backbone = create_RepVGG_B2(deploy=False)
# train_backbone.load_state_dict(torch.load('RepVGG-B2-train.pth'))
# train_pspnet = build_pspnet(backbone=train_backbone)
# segmentation_train(train_pspnet)
# deploy_pspnet = repvgg_model_convert(train_pspnet)
# segmentation_test(deploy_pspnet)
# ===================== example_pspnet.py shows an example
def repvgg_model_convert(model:torch.nn.Module, save_path=None, do_copy=True):
if do_copy:
model = copy.deepcopy(model)
for module in model.modules():
if hasattr(module, 'switch_to_deploy'):
module.switch_to_deploy()
if save_path is not None:
torch.save(model.state_dict(), save_path)
return model
csra代码块
class CSRA(nn.Module): # one basic block
def __init__(self, input_dim, num_classes, T, lam):
super(CSRA, self).__init__()
self.T = T # temperature
self.lam = lam # Lambda
self.head = nn.Conv2d(input_dim, num_classes, 1, bias=False)
self.softmax = nn.Softmax(dim=2)
def forward(self, x):
# x (B d H W)
# normalize classifier
# score (B C HxW)
score = self.head(x) / torch.norm(self.head.weight, dim=1, keepdim=True).transpose(0,1)
score = score.flatten(2)
base_logit = torch.mean(score, dim=2)
if self.T == 99: # max-pooling
att_logit = torch.max(score, dim=2)[0]
else:
score_soft = self.softmax(score * self.T)
att_logit = torch.sum(score * score_soft, dim=2)
return base_logit + self.lam * att_logit
class MHA(nn.Module): # multi-head attention
temp_settings = { # softmax temperature settings
1: [1],
2: [1, 99],
4: [1, 2, 4, 99],
6: [1, 2, 3, 4, 5, 99],
8: [1, 2, 3, 4, 5, 6, 7, 99]
}
def __init__(self, num_heads, lam, input_dim, num_classes):
super(MHA, self).__init__()
self.temp_list = self.temp_settings[num_heads]
self.multi_head = nn.ModuleList([
CSRA(input_dim, num_classes, self.temp_list[i], lam)
for i in range(num_heads)
])
def forward(self, x):
logit = 0.
for head in self.multi_head:
logit += head(x)
return logit
插入csra代码块后 将原本RepVGG
class RepVGG(nn.Module):
def __init__(self, num_blocks, num_classes=1000, width_multiplier=None, override_groups_map=None, deploy=False, use_se=False, use_checkpoint=False):
super(RepVGG, self).__init__()
......
替换成
def __init__(self, num_blocks, num_classes=1000, width_multiplier=None, override_groups_map=None, deploy=False, use_se=False, use_checkpoint=False):
super(RepVGG_csra, self).__init__()
assert len(width_multiplier) == 4
self.deploy = deploy
self.override_groups_map = override_groups_map or dict()
assert 0 not in self.override_groups_map
self.use_se = use_se
self.use_checkpoint = use_checkpoint
self.in_planes = min(64, int(64 * width_multiplier[0]))
self.stage0 = RepVGGBlock(in_channels=3, out_channels=self.in_planes, kernel_size=3, stride=2, padding=1, deploy=self.deploy, use_se=self.use_se)
self.cur_layer_idx = 1
self.stage1 = self._make_stage(int(64 * width_multiplier[0]), num_blocks[0], stride=2)
self.stage2 = self._make_stage(int(128 * width_multiplier[1]), num_blocks[1], stride=2)
self.stage3 = self._make_stage(int(256 * width_multiplier[2]), num_blocks[2], stride=2)
self.stage4 = self._make_stage(int(512 * width_multiplier[3]), num_blocks[3], stride=2)
self.gap = nn.AdaptiveAvgPool2d(output_size=1)
self.linear = nn.Linear(int(512 * width_multiplier[3]), num_classes)
self.classifier = MHA(num_classes=num_classes, input_dim=num_classes, num_heads=1, lam=0.1)
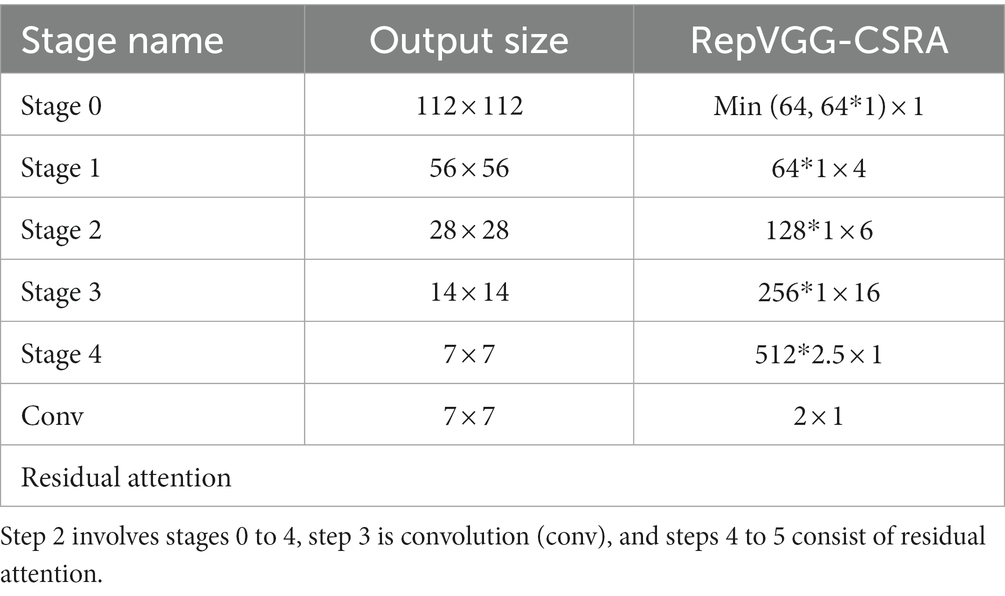
图示