本节介绍竞赛所写的网络结构
观察一下我对NET做了什么,加了很多个print,.shape的用法自己去搜,我只会和你说.shape方法就是输出tensor的shape,学会这样,方便调整你的网络。
class NET(nn.Module):
def __init__(self, len):
super(NET, self).__init__()
self.conv1 = nn.Sequential(
nn.Conv2d(in_channels=3, out_channels=8, kernel_size=5, stride=2, padding=0),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2)
)
self.conv2 = nn.Sequential(
nn.Conv2d(in_channels=8, out_channels=16, kernel_size=3, stride=1, padding=0),
nn.ReLU(),
)
self.conv3 = nn.Sequential(
nn.Conv2d(in_channels=16, out_channels=16, kernel_size=3, stride=1, padding=0),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2)
)
self.conv4 = nn.Sequential(
nn.Conv2d(in_channels=16, out_channels=24, kernel_size=3, stride=1, padding=0),
nn.ReLU(),
)
self.fc = nn.Linear(24 * 3 * 3, len)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
print(x.shape)
x = self.conv1(x)
print(x.shape)
x = self.conv2(x)
print(x.shape)
x = self.conv3(x)
print(x.shape)
x = self.conv4(x)
print(x.shape)
x = x.view(x.size(0), -1)
print(x.shape)
output = self.fc(x)
print(output.shape)
# output = self.sigmoid(x)
return output
那么问题来了,为什么要在def forward里面写呢?
这个我想说你自己悟吧,不过在你悟之前你需要知道的是,forward表示在建立模型后,进行神经元网络的前向传播。forward就是专门用来计算给定输入,得到神经元网络输出的方法,值得注意的是输入是tensor,输出也是tensor。切记,在网络里面操作的都是tensor,这个时候你就会了解到item,它就是把tensor变成你熟悉的样子。还有值得一提的是,学过了python应该知道class NET(nn.Module):意味着什么吧,nn.Module来源于pytorch,forward被pytorch赋予了特殊的含义,不能换名字嗷!
我在训练第一个epoch结束后,exit()了代码,让我们来看看输出:
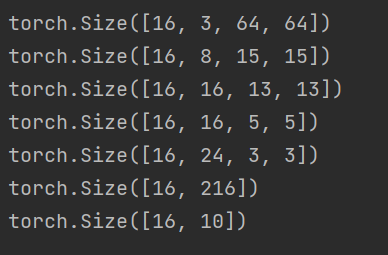
我一个一个解释一下,size展示的后面三位分别是图像的宽长高,这个时候是不是要啊? 了。
举个例子第一个size后面的三个写成常见的样子就是64×64×3,这样看是不是就眼熟了,这就是我们用transforms转换后输入的图像呀。
那么假设你是个小白的话,是不是又会存在一个问题3是怎么来的呀?
这就不得不提一嘴,学深度学习的图像处理,你需要了解图像,我了解图像是在学习深度学习之前,误打误撞学了opencv,所以opencv你也值得去了解一下嗯。这个3指的是图像的三通道,三通道我们常见的就是RGB。
言归正传
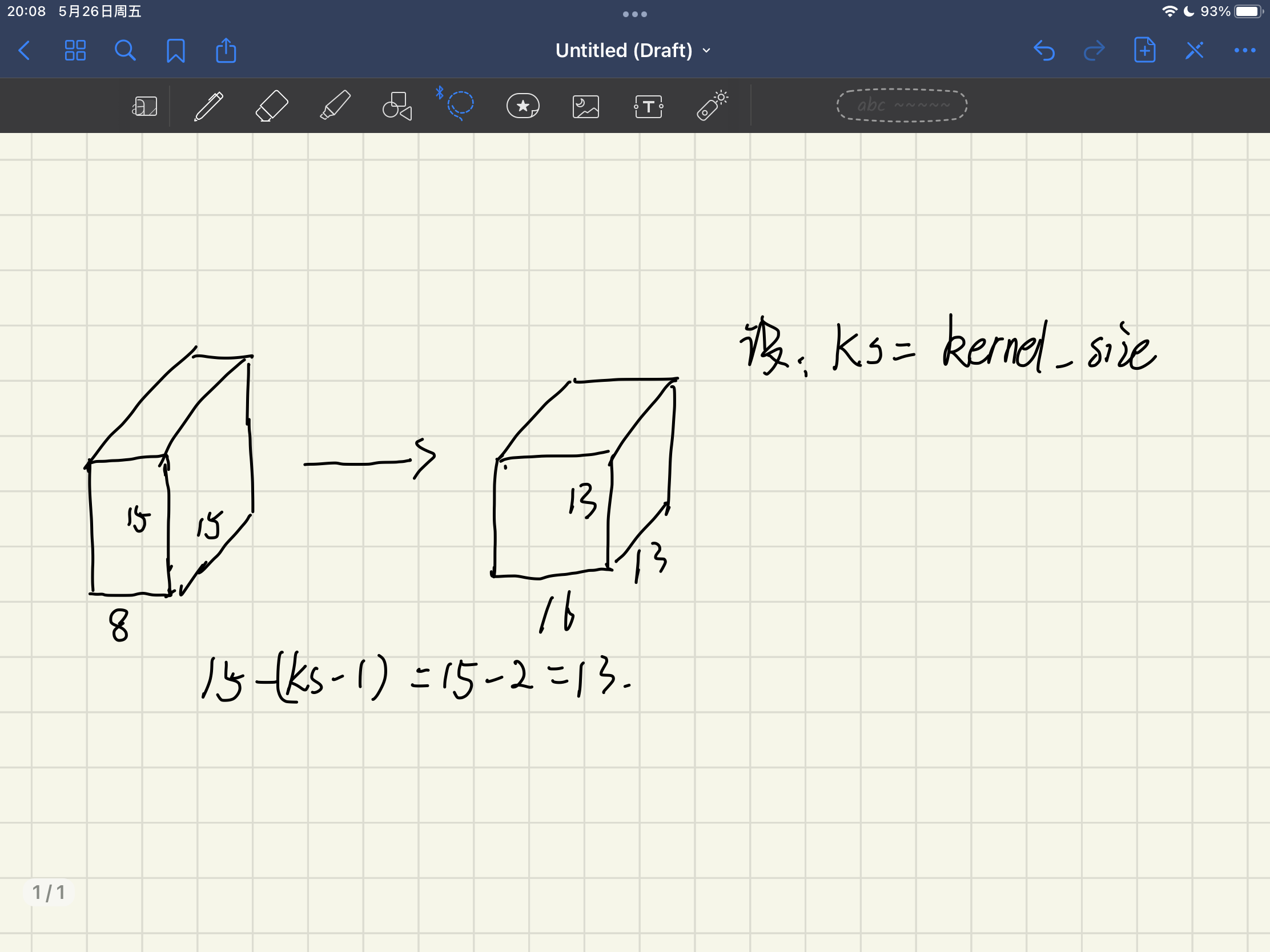
那么为什么64×64×3会变成15×15×8呢?
在解决这个问题前,我想先解释一下15×15×8会变成13×13×16
请先移步到我的另一个博客:https://zichuana.github.io/2022/12/12/layers/了解一下什么是卷积层
我假装你现在知道了什么是卷积层了:)
(不清楚可以记住计算方法,以后慢慢悟)
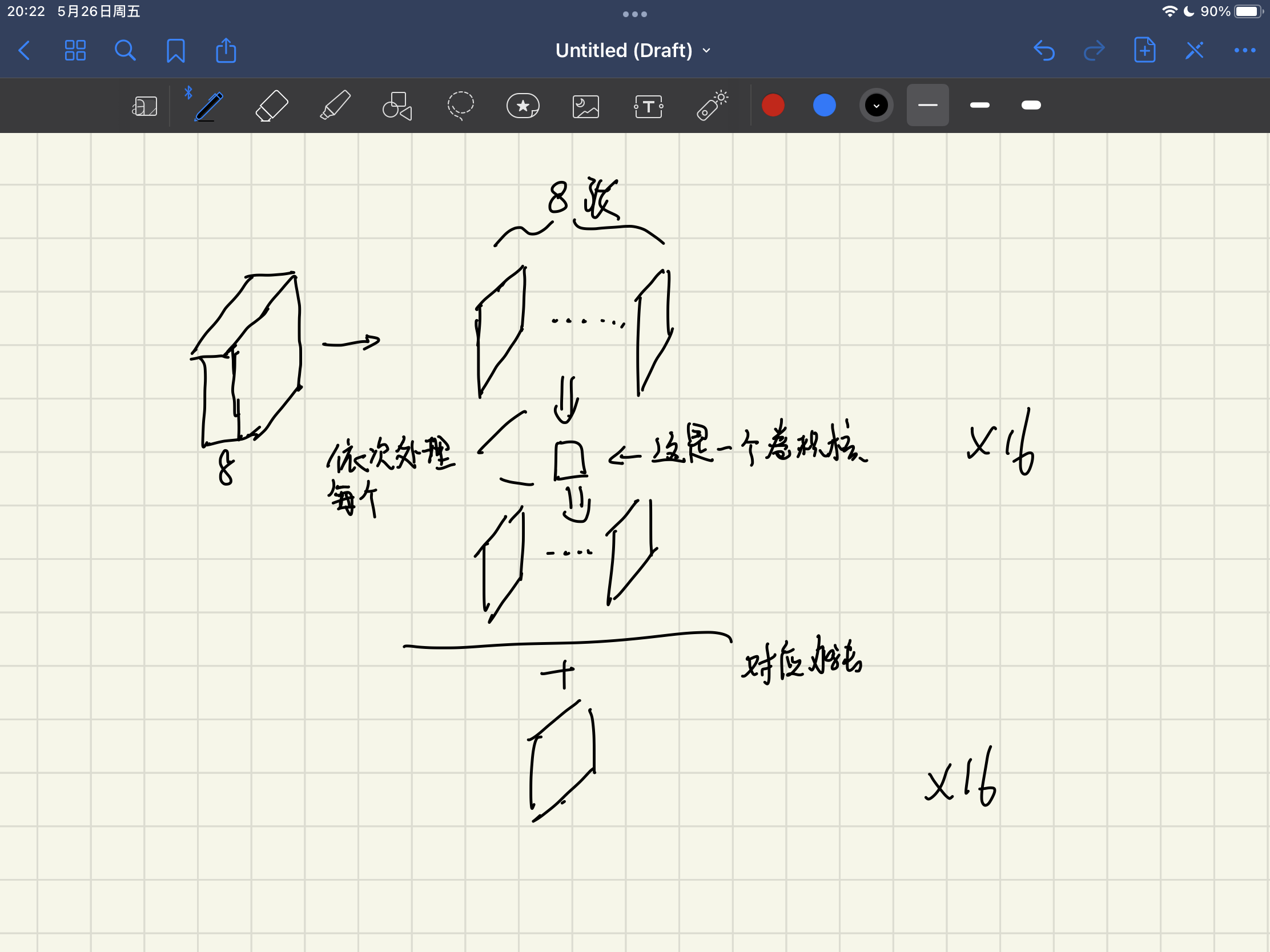
很简单,但是你需要理解,同时为什么8->16,out_channels指的是卷积核个数,有多少个卷积核就会又最后输出通道数就会是多少。可以理解层做拆分每个卷积核的命运就是去处理之前的八通道,理解成八个正方形,再将他们按照对应位置做加法就得到了一张新的单通道图,16个卷积核就得到了16个单通道图,out_channels就可以是代表是卷积核个数,绕吗画个图给你看吧:
我们再回到一开始的问题 64×64×3变成15×15×8
先计算卷积层:[64-(kernel_size-1)]/stride=[64-(5-1)]/2=30
为什么除以2这里,上一个例子stride=1这个例子stride=2,意味着步长为2,卷积核在移动的时候中间隔开了一个。
然后回到代码看看:它比刚刚那个问题还多了一个步骤MaxPool2d,那就需要你再回到https://zichuana.github.io/2022/12/12/layers/这篇博客看看什么是池化层
我假装你现在知道了什么是池化层了:)
(不清楚可以记住计算方法,以后慢慢悟)
30/kernel_size=30/2=15
注意! 这里的kernel_size卷积核大小是池化层MaxPool2d的,而上面的kernel_size卷积层Conv2d的。
之后是Linear层,最好理解的一个层,全连接层 把前面卷出来的结果压缩成我们要的样子,也就是标签的shape。
x = x.view(x.size(0), -1)
这句写在了全连接层的前面,是因为全连接层就认识将长宽高处理在一个[]里面的样子,这样就方便全连接层操作了。
也就是从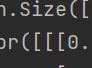 变成
变成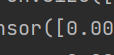
不理解的话记住就行,之后还会用的,慢慢就理解啦。
sigmoid和Relu就是两个函数,用来加速啊衔接呀各个那种客套的作用,就是数学公式。
好了让我们回到torch.Size([16, 3, 64, 64])解释完了后三个数的含义,是不是还有个疑问,16是什么意思,我们一次输入到的网络是16张。我在这之前一直在给你介绍一张图片怎么在网络里这样那样,回到上一节的DataLoader里面设置的batch_size为16,其实每一次处理的是16张。
为什么这样那样的网络就行训练后,就能学习到图像特征呢?
关于这个问题就像是现有鸡还是先有蛋一样,通常是研究人员先发现这样可以解决问题后,再开始试图解释它为什么,但是这个顺序也不完全对!嗯就是这样意思!