搜了一会没找到相关代码,自己写一个记录一下代码~
可视化RepVGG代码
from PIL import Image
from torchvision import transforms
import torch
# from model.CSRA_RepVGG import create_RepVGG_A0, create_RepVGG_B0, CSRA
from torch.utils.tensorboard import SummaryWriter
from model.RepVGG import create_RepVGG_B0
import torch.nn as nn
import matplotlib.pyplot as plt
import numpy as np
import torch.utils.checkpoint as checkpoint
savepath = 'runs/RepVGG'
def draw_features(width, height, x, savename):
fig = plt.figure(figsize=(16, 16))
fig.subplots_adjust(left=0.05, right=0.95, bottom=0.05, top=0.95, wspace=0.05, hspace=0.05)
for i in range(width * height):
plt.subplot(height, width, i + 1)
plt.axis('off')
# plt.tight_layout()
img = x[0, i, :, :]
pmin = np.min(img)
pmax = np.max(img)
img = (img - pmin) / (pmax - pmin + 0.000001)
# plt.imshow(img, cmap='gray') 觉得颜色不好看可以改成灰度的
plt.imshow(img)
print("{}/{}".format(i, width * height))
fig.savefig(savename, dpi=100)
fig.clf()
plt.close()
class ft_net(nn.Module):
def __init__(self):
super(ft_net, self).__init__()
model_ft = create_RepVGG_B0()
self.model = model_ft
self.head = nn.Conv2d(1280, 2, 1, bias=False)
self.softmax = nn.Softmax(dim=2)
def forward(self, x):
if True: # draw features or not
print(x.shape)
x = self.model.stage0(x)
print(x.shape)
draw_features(8, 8, x.cpu().numpy(), "{}/stage0.png".format(savepath))
for block in self.model.stage1:
if self.model.use_checkpoint:
x = checkpoint.checkpoint(block, x)
else:
x = block(x)
print(x.shape)
draw_features(8, 8, x.cpu().numpy(), "{}/stage1.png".format(savepath))
for block in self.model.stage2:
if self.model.use_checkpoint:
x = checkpoint.checkpoint(block, x)
else:
x = block(x)
print(x.shape)
draw_features(8, 16, x.cpu().numpy(), "{}/stage2.png".format(savepath))
for block in self.model.stage3:
if self.model.use_checkpoint:
x = checkpoint.checkpoint(block, x)
else:
x = block(x)
print(x.shape)
draw_features(16, 16, x.cpu().numpy(), "{}/stage3.png".format(savepath))
for block in self.model.stage4:
if self.model.use_checkpoint:
x = checkpoint.checkpoint(block, x)
else:
x = block(x)
draw_features(32, 40, x.cpu().numpy(), "{}/stage4.png".format(savepath))
print(x.shape)
x = self.model.gap(x)
print(x.shape)
x = x.view(x.size(0), -1)
print(x.shape)
x = self.model.linear(x)
print(x.shape)
return x
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
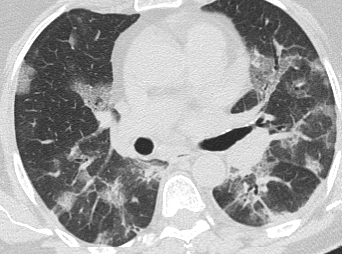
input_image = Image.open('./data3/COVID/Covid (3).png')
preprocess = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
input_tensor = preprocess(input_image)
input_batch = input_tensor.unsqueeze(0)
with torch.no_grad():
net = ft_net()
out = net(input_batch)
print(out)
RepVGG网络简单介绍
主要描述一下每一步的输出tensor
input
torch.Size([1, 3, 224, 224])
stage0conv×1
torch.Size([1, 64, 112, 112])
stage1conv×4
torch.Size([1, 64, 56, 56])
stage2conv×6
torch.Size([1, 128, 28, 28])
stage3conv×16
torch.Size([1, 256, 14, 14])
stage4conv×1
torch.Size([1, 1280, 7, 7])
pooling
torch.Size([1, 1280, 1, 1])
转换
torch.Size([1, 1280])
全连接linear
torch.Size([1, num_classes])
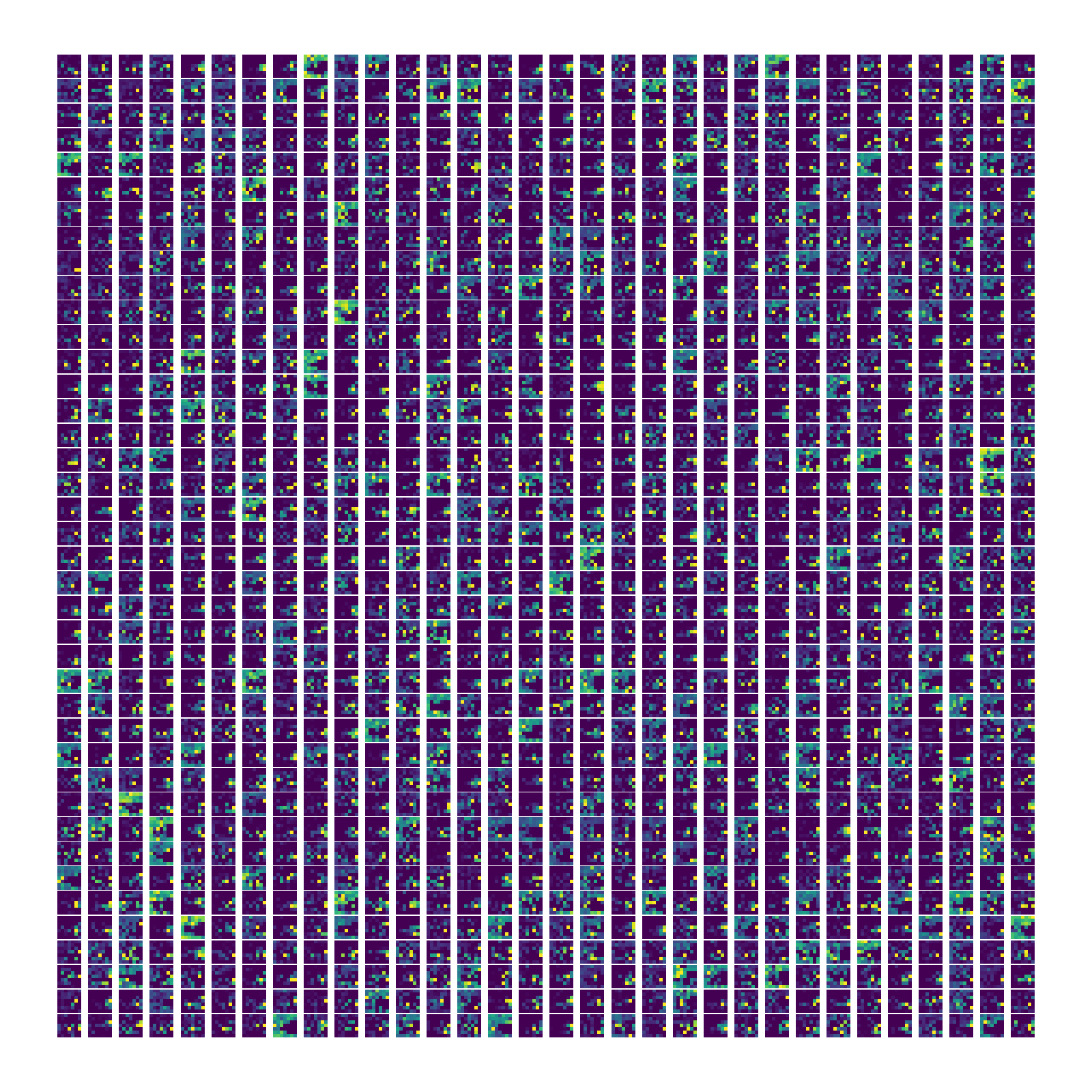
绘制结果
input
 stage0
stage0
 stage1
stage1
 stage2
stage2
 stage3
stage3
 stage4
stage4
RepVGG.py
import torch.nn as nn
import numpy as np
import torch
import copy
import torch.utils.checkpoint as checkpoint
import torch.nn.functional as F
class SEBlock(nn.Module):
def __init__(self, input_channels, internal_neurons):
super(SEBlock, self).__init__()
self.down = nn.Conv2d(in_channels=input_channels, out_channels=internal_neurons, kernel_size=1, stride=1,
bias=True)
self.up = nn.Conv2d(in_channels=internal_neurons, out_channels=input_channels, kernel_size=1, stride=1,
bias=True)
self.input_channels = input_channels
def forward(self, inputs):
x = F.avg_pool2d(inputs, kernel_size=inputs.size(3))
x = self.down(x)
x = F.relu(x)
x = self.up(x)
x = torch.sigmoid(x)
x = x.view(-1, self.input_channels, 1, 1)
return inputs * x
def conv_bn(in_channels, out_channels, kernel_size, stride, padding, groups=1):
result = nn.Sequential()
result.add_module('conv', nn.Conv2d(in_channels=in_channels, out_channels=out_channels,
kernel_size=kernel_size, stride=stride, padding=padding, groups=groups,
bias=False))
result.add_module('bn', nn.BatchNorm2d(num_features=out_channels))
return result
class RepVGGBlock(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size,
stride=1, padding=0, dilation=1, groups=1, padding_mode='zeros', deploy=False, use_se=False):
super(RepVGGBlock, self).__init__()
self.deploy = deploy
self.groups = groups
self.in_channels = in_channels
assert kernel_size == 3
assert padding == 1
padding_11 = padding - kernel_size // 2
self.nonlinearity = nn.ReLU()
if use_se:
# Note that RepVGG-D2se uses SE before nonlinearity. But RepVGGplus models uses SE after nonlinearity.
self.se = SEBlock(out_channels, internal_neurons=out_channels // 16)
else:
self.se = nn.Identity()
if deploy:
self.rbr_reparam = nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size,
stride=stride,
padding=padding, dilation=dilation, groups=groups, bias=True,
padding_mode=padding_mode)
else:
self.rbr_identity = nn.BatchNorm2d(
num_features=in_channels) if out_channels == in_channels and stride == 1 else None
self.rbr_dense = conv_bn(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size,
stride=stride, padding=padding, groups=groups)
self.rbr_1x1 = conv_bn(in_channels=in_channels, out_channels=out_channels, kernel_size=1, stride=stride,
padding=padding_11, groups=groups)
print('RepVGG Block, identity = ', self.rbr_identity)
def forward(self, inputs):
if hasattr(self, 'rbr_reparam'):
return self.nonlinearity(self.se(self.rbr_reparam(inputs)))
if self.rbr_identity is None:
id_out = 0
else:
id_out = self.rbr_identity(inputs)
return self.nonlinearity(self.se(self.rbr_dense(inputs) + self.rbr_1x1(inputs) + id_out))
# Optional. This may improve the accuracy and facilitates quantization in some cases.
# 1. Cancel the original weight decay on rbr_dense.conv.weight and rbr_1x1.conv.weight.
# 2. Use like this.
# loss = criterion(....)
# for every RepVGGBlock blk:
# loss += weight_decay_coefficient * 0.5 * blk.get_cust_L2()
# optimizer.zero_grad()
# loss.backward()
def get_custom_L2(self):
K3 = self.rbr_dense.conv.weight
K1 = self.rbr_1x1.conv.weight
t3 = (self.rbr_dense.bn.weight / ((self.rbr_dense.bn.running_var + self.rbr_dense.bn.eps).sqrt())).reshape(-1,
1, 1,
1).detach()
t1 = (self.rbr_1x1.bn.weight / ((self.rbr_1x1.bn.running_var + self.rbr_1x1.bn.eps).sqrt())).reshape(-1, 1, 1,
1).detach()
l2_loss_circle = (K3 ** 2).sum() - (K3[:, :, 1:2,
1:2] ** 2).sum() # The L2 loss of the "circle" of weights in 3x3 kernel. Use regular L2 on them.
eq_kernel = K3[:, :, 1:2, 1:2] * t3 + K1 * t1 # The equivalent resultant central point of 3x3 kernel.
l2_loss_eq_kernel = (eq_kernel ** 2 / (
t3 ** 2 + t1 ** 2)).sum() # Normalize for an L2 coefficient comparable to regular L2.
return l2_loss_eq_kernel + l2_loss_circle
# This func derives the equivalent kernel and bias in a DIFFERENTIABLE way.
# You can get the equivalent kernel and bias at any time and do whatever you want,
# for example, apply some penalties or constraints during training, just like you do to the other models.
# May be useful for quantization or pruning.
def get_equivalent_kernel_bias(self):
kernel3x3, bias3x3 = self._fuse_bn_tensor(self.rbr_dense)
kernel1x1, bias1x1 = self._fuse_bn_tensor(self.rbr_1x1)
kernelid, biasid = self._fuse_bn_tensor(self.rbr_identity)
return kernel3x3 + self._pad_1x1_to_3x3_tensor(kernel1x1) + kernelid, bias3x3 + bias1x1 + biasid
def _pad_1x1_to_3x3_tensor(self, kernel1x1):
if kernel1x1 is None:
return 0
else:
return torch.nn.functional.pad(kernel1x1, [1, 1, 1, 1])
def _fuse_bn_tensor(self, branch):
if branch is None:
return 0, 0
if isinstance(branch, nn.Sequential):
kernel = branch.conv.weight
running_mean = branch.bn.running_mean
running_var = branch.bn.running_var
gamma = branch.bn.weight
beta = branch.bn.bias
eps = branch.bn.eps
else:
assert isinstance(branch, nn.BatchNorm2d)
if not hasattr(self, 'id_tensor'):
input_dim = self.in_channels // self.groups
kernel_value = np.zeros((self.in_channels, input_dim, 3, 3), dtype=np.float32)
for i in range(self.in_channels):
kernel_value[i, i % input_dim, 1, 1] = 1
self.id_tensor = torch.from_numpy(kernel_value).to(branch.weight.device)
kernel = self.id_tensor
running_mean = branch.running_mean
running_var = branch.running_var
gamma = branch.weight
beta = branch.bias
eps = branch.eps
std = (running_var + eps).sqrt()
t = (gamma / std).reshape(-1, 1, 1, 1)
return kernel * t, beta - running_mean * gamma / std
def switch_to_deploy(self):
if hasattr(self, 'rbr_reparam'):
return
kernel, bias = self.get_equivalent_kernel_bias()
self.rbr_reparam = nn.Conv2d(in_channels=self.rbr_dense.conv.in_channels,
out_channels=self.rbr_dense.conv.out_channels,
kernel_size=self.rbr_dense.conv.kernel_size, stride=self.rbr_dense.conv.stride,
padding=self.rbr_dense.conv.padding, dilation=self.rbr_dense.conv.dilation,
groups=self.rbr_dense.conv.groups, bias=True)
self.rbr_reparam.weight.data = kernel
self.rbr_reparam.bias.data = bias
self.__delattr__('rbr_dense')
self.__delattr__('rbr_1x1')
if hasattr(self, 'rbr_identity'):
self.__delattr__('rbr_identity')
if hasattr(self, 'id_tensor'):
self.__delattr__('id_tensor')
self.deploy = True
class RepVGG(nn.Module):
def __init__(self, num_blocks, num_classes=1000, width_multiplier=None, override_groups_map=None, deploy=False,
use_se=False, use_checkpoint=False):
super(RepVGG, self).__init__()
assert len(width_multiplier) == 4
self.deploy = deploy
self.override_groups_map = override_groups_map or dict()
assert 0 not in self.override_groups_map
self.use_se = use_se
self.use_checkpoint = use_checkpoint
self.in_planes = min(64, int(64 * width_multiplier[0]))
self.stage0 = RepVGGBlock(in_channels=3, out_channels=self.in_planes, kernel_size=3, stride=2, padding=1,
deploy=self.deploy, use_se=self.use_se)
self.cur_layer_idx = 1
self.stage1 = self._make_stage(int(64 * width_multiplier[0]), num_blocks[0], stride=2)
self.stage2 = self._make_stage(int(128 * width_multiplier[1]), num_blocks[1], stride=2)
self.stage3 = self._make_stage(int(256 * width_multiplier[2]), num_blocks[2], stride=2)
self.stage4 = self._make_stage(int(512 * width_multiplier[3]), num_blocks[3], stride=2)
self.gap = nn.AdaptiveAvgPool2d(output_size=1)
self.linear = nn.Linear(int(512 * width_multiplier[3]), num_classes)
def _make_stage(self, planes, num_blocks, stride):
strides = [stride] + [1] * (num_blocks - 1)
blocks = []
for stride in strides:
cur_groups = self.override_groups_map.get(self.cur_layer_idx, 1)
blocks.append(RepVGGBlock(in_channels=self.in_planes, out_channels=planes, kernel_size=3,
stride=stride, padding=1, groups=cur_groups, deploy=self.deploy,
use_se=self.use_se))
self.in_planes = planes
self.cur_layer_idx += 1
return nn.ModuleList(blocks)
def forward(self, x):
out = self.stage0(x)
for stage in (self.stage1, self.stage2, self.stage3, self.stage4):
for block in stage:
if self.use_checkpoint:
out = checkpoint.checkpoint(block, out)
else:
out = block(out)
print(out.shape)
out = self.gap(out)
print(out.shape)
out = out.view(out.size(0), -1)
print(out.shape)
out = self.linear(out)
print(out.shape)
return out
optional_groupwise_layers = [2, 4, 6, 8, 10, 12, 14, 16, 18, 20, 22, 24, 26]
g2_map = {l: 2 for l in optional_groupwise_layers}
g4_map = {l: 4 for l in optional_groupwise_layers}
def create_RepVGG_A0(deploy=False, use_checkpoint=False):
return RepVGG(num_blocks=[2, 4, 14, 1], num_classes=1000,
width_multiplier=[0.75, 0.75, 0.75, 2.5], override_groups_map=None, deploy=deploy,
use_checkpoint=use_checkpoint)
def create_RepVGG_A1(deploy=False, use_checkpoint=False):
return RepVGG(num_blocks=[2, 4, 14, 1], num_classes=1000,
width_multiplier=[1, 1, 1, 2.5], override_groups_map=None, deploy=deploy,
use_checkpoint=use_checkpoint)
def create_RepVGG_A2(deploy=False, use_checkpoint=False):
return RepVGG(num_blocks=[2, 4, 14, 1], num_classes=1000,
width_multiplier=[1.5, 1.5, 1.5, 2.75], override_groups_map=None, deploy=deploy,
use_checkpoint=use_checkpoint)
def create_RepVGG_B0(deploy=False, use_checkpoint=False):
return RepVGG(num_blocks=[4, 6, 16, 1], num_classes=1000,
width_multiplier=[1, 1, 1, 2.5], override_groups_map=None, deploy=deploy,
use_checkpoint=use_checkpoint)
def create_RepVGG_B1(deploy=False, use_checkpoint=False):
return RepVGG(num_blocks=[4, 6, 16, 1], num_classes=1000,
width_multiplier=[2, 2, 2, 4], override_groups_map=None, deploy=deploy, use_checkpoint=use_checkpoint)
def create_RepVGG_B1g2(deploy=False, use_checkpoint=False):
return RepVGG(num_blocks=[4, 6, 16, 1], num_classes=1000,
width_multiplier=[2, 2, 2, 4], override_groups_map=g2_map, deploy=deploy,
use_checkpoint=use_checkpoint)
def create_RepVGG_B1g4(deploy=False, use_checkpoint=False):
return RepVGG(num_blocks=[4, 6, 16, 1], num_classes=1000,
width_multiplier=[2, 2, 2, 4], override_groups_map=g4_map, deploy=deploy,
use_checkpoint=use_checkpoint)
def create_RepVGG_B2(deploy=False, use_checkpoint=False):
return RepVGG(num_blocks=[4, 6, 16, 1], num_classes=1000,
width_multiplier=[2.5, 2.5, 2.5, 5], override_groups_map=None, deploy=deploy,
use_checkpoint=use_checkpoint)
def create_RepVGG_B2g2(deploy=False, use_checkpoint=False):
return RepVGG(num_blocks=[4, 6, 16, 1], num_classes=1000,
width_multiplier=[2.5, 2.5, 2.5, 5], override_groups_map=g2_map, deploy=deploy,
use_checkpoint=use_checkpoint)
def create_RepVGG_B2g4(deploy=False, use_checkpoint=False):
return RepVGG(num_blocks=[4, 6, 16, 1], num_classes=1000,
width_multiplier=[2.5, 2.5, 2.5, 5], override_groups_map=g4_map, deploy=deploy,
use_checkpoint=use_checkpoint)
def create_RepVGG_B3(deploy=False, use_checkpoint=False):
return RepVGG(num_blocks=[4, 6, 16, 1], num_classes=1000,
width_multiplier=[3, 3, 3, 5], override_groups_map=None, deploy=deploy, use_checkpoint=use_checkpoint)
def create_RepVGG_B3g2(deploy=False, use_checkpoint=False):
return RepVGG(num_blocks=[4, 6, 16, 1], num_classes=1000,
width_multiplier=[3, 3, 3, 5], override_groups_map=g2_map, deploy=deploy,
use_checkpoint=use_checkpoint)
def create_RepVGG_B3g4(deploy=False, use_checkpoint=False):
return RepVGG(num_blocks=[4, 6, 16, 1], num_classes=1000,
width_multiplier=[3, 3, 3, 5], override_groups_map=g4_map, deploy=deploy,
use_checkpoint=use_checkpoint)
def create_RepVGG_D2se(deploy=False, use_checkpoint=False):
return RepVGG(num_blocks=[8, 14, 24, 1], num_classes=1000,
width_multiplier=[2.5, 2.5, 2.5, 5], override_groups_map=None, deploy=deploy, use_se=True,
use_checkpoint=use_checkpoint)
func_dict = {
'RepVGG-A0': create_RepVGG_A0,
'RepVGG-A1': create_RepVGG_A1,
'RepVGG-A2': create_RepVGG_A2,
'RepVGG-B0': create_RepVGG_B0,
'RepVGG-B1': create_RepVGG_B1,
'RepVGG-B1g2': create_RepVGG_B1g2,
'RepVGG-B1g4': create_RepVGG_B1g4,
'RepVGG-B2': create_RepVGG_B2,
'RepVGG-B2g2': create_RepVGG_B2g2,
'RepVGG-B2g4': create_RepVGG_B2g4,
'RepVGG-B3': create_RepVGG_B3,
'RepVGG-B3g2': create_RepVGG_B3g2,
'RepVGG-B3g4': create_RepVGG_B3g4,
'RepVGG-D2se': create_RepVGG_D2se, # Updated at April 25, 2021. This is not reported in the CVPR paper.
}
def get_RepVGG_func_by_name(name):
return func_dict[name]
# Use this for converting a RepVGG model or a bigger model with RepVGG as its component
# Use like this
# model = create_RepVGG_A0(deploy=False)
# train model or load weights
# repvgg_model_convert(model, save_path='repvgg_deploy.pth')
# If you want to preserve the original model, call with do_copy=True
# ====================== for using RepVGG as the backbone of a bigger model, e.g., PSPNet, the pseudo code will be like
# train_backbone = create_RepVGG_B2(deploy=False)
# train_backbone.load_state_dict(torch.load('RepVGG-B2-train.pth'))
# train_pspnet = build_pspnet(backbone=train_backbone)
# segmentation_train(train_pspnet)
# deploy_pspnet = repvgg_model_convert(train_pspnet)
# segmentation_test(deploy_pspnet)
# ===================== example_pspnet.py shows an example
def repvgg_model_convert(model: torch.nn.Module, save_path=None, do_copy=True):
if do_copy:
model = copy.deepcopy(model)
for module in model.modules():
if hasattr(module, 'switch_to_deploy'):
module.switch_to_deploy()
if save_path is not None:
torch.save(model.state_dict(), save_path)
return model